Here’s a link to part 1 of this series.
Generating the abstract syntax tree
Generating the AST from the instruction node tree ends up being fairly straightforward.
SCI Companion has the following syntax nodes (that appear in the AST): value (these can be tokens, strings, saids, selectors or numbers), complex value (like value, but allows for an indexer if it’s a token), assignment, variable declaration, define, class property, function, class definition, synonym, code block, send param, L-value, send call, procedure call, condition expression (old syntax only), case, switch, asm statement, asm block, return, binary operation, unary operation, n-ary operation, for loop, while loop, do loop, break statement, continue statement, rest statement, script, comment, function parameter, function signature, if, export, cond statement.
For most of the control structures in the tree, there ends up being a straight mapping to a particular type of syntax node.
For sequences of raw instructions (that don’t affect control flow), it becomes just slightly more involved:
ldi, pushi, push0, push1, push2
These end up simply being numeric values:
ldi 3
aTop cycles
(= cycles 3)
callk, callb, calle, call
These become procedure calls:
push2
push0
pushi 3
callk Random 4
(Random 0 3)
send, self, super
These are a little more involved, since they may have multiple send params for a single send target. Each one has a parameter count associated with it, and we need to assume that we can get a numeric value for the instruction that designates the parameter count.
pushi 28 // $28 number
push1
pushi 96 // 150
pushi 3 // $3 loop
push1
pushi ff // -1
pushi 27 // $27 play
push1
pushSelf
lag gGlobalSound
send 12
(gGlobalSound number: 150 loop: -1 play: self)
lsub, mul, div, mod, shr, shl, xor, and, or, add, eq, gt, lt, le, ne, ge, ugt, uge, ult, ule
These become binary operations:
pTos state
ldi 2
add
(+ state 2)
bnot, not, neg
These become unary operations:
lal local1
not
(not local1)
rest
Simply a rest statement:
pushi 6e // $6e init
push0
&rest 1
super KQ6Room 4
(super init: &rest)
lea
Becomes a value that is marked as being a pointer (and possibly has an indexer):
lea local13
@local13
class, pushself
Become values that are marked as tokens:
pushi 51 // $51 delete
push1
pushSelf
lag gKq6WalkHandler
send 6
(gKq6WalkHandler delete: self)
lofsa, lofss
Become values that are marked as literal strings, saids, or tokens depending on the numeric value they reference (we need to reference the script resource to find out):
push2
lofss $0644 // *** ... well, Okay.
lofss $0542 // lampStartScript
calle 399 procedure_0000 3 // proc921_0
(proc921_0 {*** ... well, Okay} lampStartScript)
atop, stop
These become assignment operations. We need to reference the script resource here to look up the property name, since these instructions use a property index which pertains to the “current” object.
lap param1
aTop state
(= state param1)
ptos, ptoa
Instructions to read from class properties. Similar to above in that we need to look up the property name, but these are simply values marked as tokens.
pTos state
ldi 5
gt?
(> state 5)
iptoa, dptoa, iptos, dptos
Similar to the above, but this ends up being a unary operation (– or ++):
dpToa state
(-- state)
ret
Becomes a return statement.
selfID
Becomes a property value for a “self” token (selfID puts a pointer to self in the accumulator, while pushSelf puts it on the stack):
selfID
sal local8
(= local8 self)
push, pprev
These just forward onto their only child (which will have an instruction that sets the accumulator, or the prev register in the case of pprev). push just pushes the accumulator value onto the stack. Since the abstract syntax tree doesn’t care about stack vs accumulator (it’s an implementation detail of the byte code, so to speak), we basically ignore it. We already took it into account when generating the instruction consumption tree.
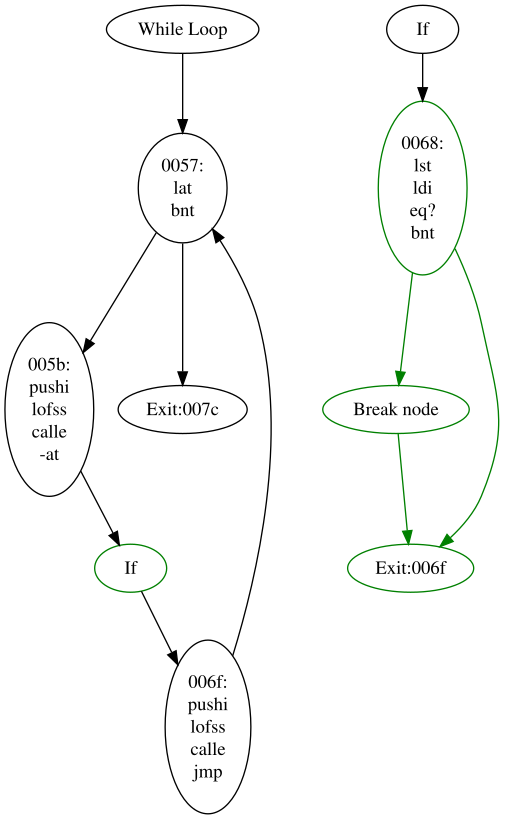
bt, bnt
These are essentially ignored at this stage (they were taken into consideration in the control flow graph), and just forward on to their only child.
dup, jmp, link
These can also be ignored at this stage.
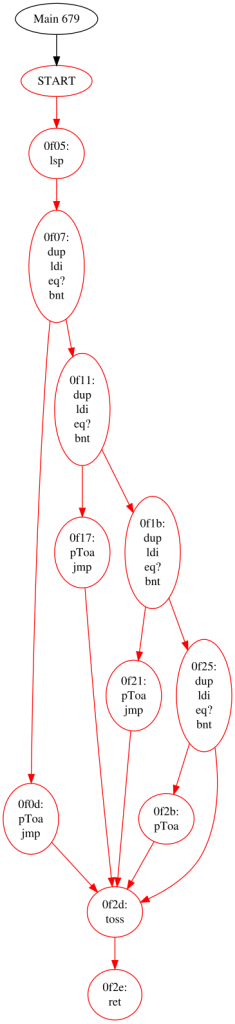
toss
This indicates the end of a switch statement. These should have already been pruned (and their surrounding code should already be in the form of a switch stratement in the control flow graph), but there are cases where we have mid-identified degenerate switch statements. So if we encounter this, we generate a switch statement with a single (default) case.
Others…
The rest of the instructions involve load and store operations for global, local, temporary and parameter variables. So it is a matter of creating assignment operations (for the store opcodes) or values (for the load opcodes), and looking up the appropriate variable name.
ldi 0
sat temp0
lst temp0
ldi 6
lt?
bnt code_0101
(= temp0 0)
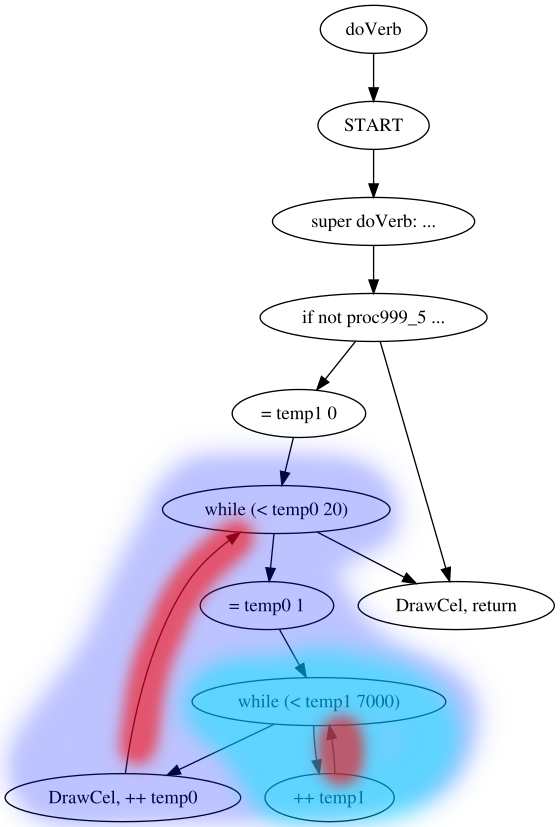
(while (< temp0 6)
...
)
Naming and symbol resolution
We’ve glossed over this so far, but coming up with the correct meaningful names for variables and tokens is important (not just for decompiling, but also disassembling).
There are a few different categories here:
- names we can find out for certain (class names, instance names, property names)
- names for which we have no information at all (local variable names)
- values in the code that refer to objects, strings or selectors. All values are just 16-bit numbers, but some of them are pointers, and we need to try to replace them with the correct textual value.
Let’s go over each of them in more detail.
Known symbol lookups
The script resources themselves contain the names for classes and instances defined in that script – that’s pretty straightforward. We also need to reference superclasses though. They are generally referred to by their class number (just a 16-bit value).
SCI games have a class table resource that lists that basically maps a number to an index within a particular script resource. For instance, class #33 might be the 2nd class defined in script 988. For this reason, to build a mapping of class number to class name, we need to actually load all script resources in the game (or at least all those listed in the class table resource) and search for the class name. This table that we construct is actually fundamental not just for decompiling, but also compiling.
For property and method names, it is a little easier. Both properties and methods are identified by their selector number. SCI games have a selector table resource that is a direct mapping of selector number to selector names.
Heuristics for generating meaningful variable names
Unfortunately, there is no trace left of the original variable names in the compiled byte code. That means we don’t know the names for global variables, script variables, temporary function variables or parameters.
We do know which type of variable something is though, and we know its index. When the abstract syntax tree is generated during decompilation, automatic variable names are generated that simply combine the variable type and index: global25, or temp1, say.
We then perform a renaming pass that attempts to give more meaningful names. The following things happen:
- We leverage an editable decompile.ini file which lists known parameter names for certain methods. For instance, it will name the first parameter to the commonly-overridden changeState method “newState”. Likewise, handleEvent’s first parameter is “pEvent”.
- The first bunch of global variables tend to be the same across games, so we have a pre-defined list of what these should be named.
- The first assignment to a variable in a function will attempt to generate a name based of what was assigned to it. For instance, if we see “(= temp0 x)“, we’ll rename temp0 to “theX“. It’s not perfect, but at least it helps give some indication as to what the variable might be used for.
- When we assign to global variables, we store that information so that it may be re-used by subsequent scripts. For instance, if we encounter the code “(= global75 features)“, we’ll rename global75 to “gFeatures“. This will be picked up by further decompiles of scripts that reference global75.
- The user can also guide the renaming of global variables and public procedures by giving them new names during the decompilation process.
Naming constants
Of course, it’s not only variables that need good names. We also want constants to be properly defined.
For instance, the Palette kernel call takes a subfunction as its first parameter. This is just a number, but there are eight different functions it might represent. sci.sh, the global header file, as these defined. Using the decompiler.ini file, we can indicate that the first parameter to Palette is one of these defines. That allows the decompiler to turn this:
(Palette 1 97)
into this:
(Palette palSET_FROM_RESOURCE 97)
We can also do this for variables of certain names. For instance, we can say the type property of a variable called pEvent should be one of the event type enumeration values defined in sci.sh. This lets us produce code like this, where it’s clear we’re handling mouse events:
(method (handleEvent pEvent)
(if (== (pEvent type?) evMOUSEBUTTON)
(if
(and
(User controls?)
(not script)
(== (pEvent type?) evMOUSEBUTTON)
)
(gEgo setMotion: theSMover (pEvent x?) (gEgo y?))
(pEvent claimed: 1)
)
else
(super handleEvent: pEvent)
)
)
Another scenario in which the decompiler.ini config file is useful is to identify parameters which might be selector literals. Some of the fundamental methods on the SCI object base class take selector literals as parameters (for example, the firstTrue method). From the decompiler’s standpoint, the value passed to this method is just a number. But we can tag it as being a selector so that we can generate more meaningful code at the call site. An example from Space Quest 1 VGA, where we know that the first value passed to the firstTrue method is a selector:
(= temp0 (gCast firstTrue: #isKindOf Elevator))
This is assigning the first cast member that is a subclass of Elevator to the temp0 variable.
Defining these values/types for just a handful of common scenarios goes a long way to generating readable code right off the bat.
Another important scenario where we need to make some guesses is in the instance property lists. When an object instance is defined, you can override the default property values for its species. This property value is a 16-bit number as always – but it might be an offset into the script’s string table or said table. How can we know this? We can’t know for sure (we could get some false positives), but every property value is checked to see if its value matches one of those offsets. As a result, inventory items decompile correctly:
(instance Grenade of RInvItem
(properties
view 564
cursor 16
signal $0002
description "You have a small innocuous looking grenade."
owner 58
)
)
Array bounds
As mentioned before, variables are referenced in byte code by their type and index. The notion of arrays doesn’t really exist. A function or a script just declares that it has, say, 10 variable slots. These could be 10 single variables, or perhaps 5 single variables and a 5 element array.
However, by examining how these variables are used we can get an idea of which parts of the variable block are explicitly referenced, and which parts are only referenced by index. As an example, in script 40 of Space Quest 1 VGA, we encounter this code:
(holePoly points: @local1 size: 8)
(shipPoly points: @local17 size: 8)
By examining this and other local variable usage, we come up with the following list of local variables, two of which we define as arrays (they appear to be lists of polygon coordinates).
(local
local0
[local1 16] = [178 169 196 162 222 160 256 164 265 168 253 177 220 182 189 178]
[local17 16] = [178 171 177 155 222 150 264 157 269 170 242 170 232 177 201 170]
gEgoEdgeHit
local34
)
Parameters
Unlike temp, local and global variables, there is no explicit count of function parameters anywhere in the byte code. This makes sense, because SCI allows for a variable number of parameters for all functions. As a result, we need to scan the function for code that references parameters (like other variable types, they are referenced by index), and any usages of a rest instruction (which forwards unspecified parameters onto another function). From this information we can figure out the number of named parameters.
Function return values
In SCI, functions return values via the accumulator. The byte code offers no hint as to whether a function intentionally returns a value or not.
We make some attempt at guessing. If we encounter an opcode with no side effects (i.e. all it does is put something in the accumulator – no functions called or properties set) that is right before a ret instruction, then we’ll assume the function intentionally returns a value. This will affect how we generate the instruction consumption tree: ret instructions will consume the accumulator.
Our guess isn’t correct all of the time, but it ends up not really mattering from an accuracy point of view. The re-compiled code should still exhibit the same behavior (in terms of what’s “accidentally” left in the accumulator at function exit) as the original byte code.
Number formatting
Numeric literals in source code may be specified in decimal or hexadecimal (or binary, or by ASCII character). And they may be signed or unsigned.
In the AST, numeric literals are represented by a value node. The numeric value is always stored as an unsigned 16-bit value, but it can be tagged as being “negative”, or in “hex”. This doesn’t change the underlying value, it’s simply a clue as to how to present it when formatting it for output.
Of course, we usually have no explicit information in the byte code that helps us decide which way to output the number. As result, we need to apply some simple heuristics:
Any value that is a direct child of a bit-wise operation (whether it be a binary, unary or assignment operation) will be tagged as “hex”.
(method (enable param1)
(if param1
(= state (| state $0001))
else
(= state (& state $fffe))
)
)
Currently, any value that is larger than 32767 (the largest signed 16-bit value) will be tagged as negative. Obviously this isn’t always the right choice, but it tends to be.
setMotion: MoveTo -108 224
Tracking script dependencies
Compiling an SCI script requires that any scripts than contain referenced classes or procedures from other scripts have those other scripts’ filenames listed in the use statements at the top of the script being compiled.
Thus, to generate a perfectly-compilable script, we need to scan all code and classes for references to public procedures and class names. Then we need to figure out the names of those scripts where they reside and add in the appropriate use statement in the AST.
Failure
The decompiler isn’t perfect, but typically it can decompile about 95 to 99 percent of a game into source code. Success is typically on a function-by-function basis. Luckily, if an error or unexpected condition occurs anywhere during the decompilation of a function, we can have the entire function fallback to assembly. This at least retains the ability to recompile code correctly, and also retains some symbol information. An example from Space Quest 1 VGA, Talker::startAudio:
(method (startAudio param1 &tmp temp0)
(asm
lap param1
sat temp0
pushi 2
pushi 1
push
callk DoAudio, 4
pToa mouth
bnt code_0452
pushi #setCycle
pushi 2
class 40
push
lst temp0
pToa mouth
send 8
code_0452:
pushi 2
pushi 2
lst temp0
callk DoAudio, 4
aTop ticks
pToa eyes
bnt code_046d
pushi #setCycle
pushi 2
class RTRandCycle
push
pTos ticks
pToa eyes
send 8
code_046d:
ret
)
)
Note that I actually had to add an additional opcode that isn’t present in SCI. the lea opcode loads the address of a variable into the accumulator. It can also have a flag that indicates “use the previous value in the accumulator as an array index”. I could have changed symbol resolution for the operands to support referencing the accumulator, but the most straightforward choice was just to add an additional opcode called “leai“, which is handled specially during disassembly and compiling.
With a bunch more work, it should be possible to have the decompiler 100% effective (except for corrupted scripts, of course) – but I decided that the effort vs reward wasn’t worth it beyond this point, especially given the fallback to assembly. It’s good enough to be able to create a template game from and for people to easily write script patches or mods to existing games.
Code output
SCI Companion supports both the source code syntax of SCI Studio, and also a newer syntax that is much closer to that used by Sierra originally.
There are modules that output source code in either of these formats based on the given abstract syntax tree. However, there isn’t necessarily a one-to-one mapping of syntax nodes to source code. The abstract syntax tree code was mostly written when only the SCI Studio syntax existed. Some of the forms don’t map quite as nicely (or can be expressed more efficiently) in the Sierra syntax. Since the Sierra syntax is the preferred syntax, we’ll go through some of the additional transformations we do on the syntax tree as we’re formatting it as source code.
Do-loops don’t exist in the Sierra syntax, so they need to be converted into repeat statements that end with a breakif statement in place of the do-loop condition. An example:
(repeat
((= param1 (Event new: -32768)) localize:)
(if (!= (= temp0 (self check: param1)) temp1)
(HiliteControl self)
(= temp1 temp0)
)
(param1 dispose:)
(breakif (not (localproc_0022)))
)
While-loops that are determined to be infinite are just converted to repeat statements.
Sierra syntax has a shorthand for nested if-then-else clauses: the LISP-like cond statement. When outputting an if-statement, if nested if-statements are detected, we use the cond syntax instead:
(cond
((& (gEgo onControl:) ctlYELLOW) (Print {You can't do that from here.}))
((& (gEgo onControl:) ctlFUCHSIA) (gEgo setScript: egoTouchesAcid))
((== global166 1) (Print {You can't do that from here.}))
)
Sierra syntax supports n-ary operations for several operators, whereas the SCI Syntax only supports binary operations. If nested binary operations are found, we try to coalesce them into an n-ary operation (e.g. (+ a b c)).
The if-then-break and if-then-continue forms are turned into the Sierra-specific breakif and contif statements.
Another thing to note is that there are some forms the decompiler will never generate:
- No for-loops are ever generated, as they are simply while loops with some initialization code prior to the loop start. With some extra effort I could have tried to guess what code should be put into a for-loop‘s initialization and afterthought parts, but I did not deem the value worth the effort.
- Operator assignments like += or -= will never be generated (they will just retain the regular form (= a (+ a 1))). Another “nice to have” but not essential feature.
- The Sierra syntax supports a switchto statement with implied case values (starting from 0). The decompiler will always just output switch statements, however (which have explicit case values).
- The Sierra syntax supports (rarely-used) multilevel break and continue statements, but these will never be output. In fact, the control flow analysis does not handle these properly, and so decompilation will likely fail if this pattern is encountered. This will cause us to fall back to assembly.
Summary
Hopefully this has been an educational walk-through of the details involved in going from byte code to source code.
There are of course more subtleties and complexities that I have glossed over in these blog posts, but the SCI Companion source code is available for perusal.